
0과 1 사이
손동작 인식 원리 본문
손동작을 어떻게 인식할 수 있을까?
다양한 방법을 찾아봤다.
대부분은 피부색의 범위를 설정해놓고 그에 부합하는 영역을 검출하는 방식이다. 그렇기 때문에 배경이 살색과 비슷할 경우 손동작을 검출하기 어려움.
테스트 결과
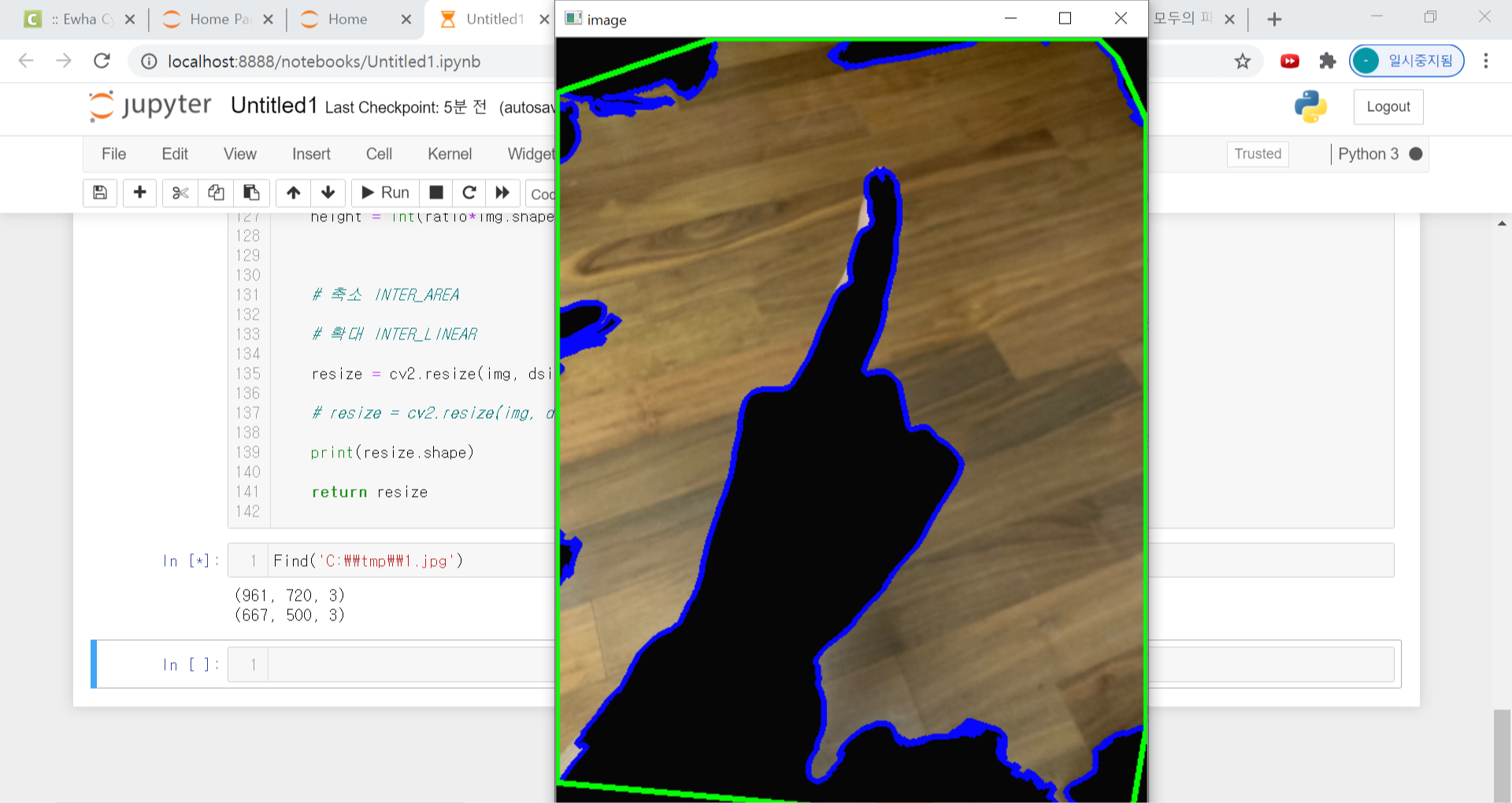

각각 다른 코드로 테스트 해봤다.
첫번째는 배경도 같이 검출되고, 두번째는 잡음이 심한 단점이 있다.
사실 참고한 코드가 작동을 안해서 어떻게든 동작하게 만들다 보니.. 결과가 좋지는 않은듯
이 코드의 대략적 알고리즘은 이렇다.
얼굴 인식 -> 얼굴에 해당하는 부분 제거 -> 살색 검출을 통해 손 인식 -> 경계선 검출 -> 손끝점 인식
가장 핵심적인 경계선 검출 알고리즘에 대해 이해한 바를 얘기해보겠다.

손가락 인식 파트에서 가장 중요한 기술은 손의 경계선을 검출하는 것이다. 화면과 같은 지구의 경계선을 검출한다고 가정할 때, 우선 동일한 색상을 가진 부분의 가장자리를 연결하여, 영역을 나눈다. 그후 이미지 전체를 회색조의 이미지로 변환한다. 이때 찾으려는 부분은 흰색으로 변환하고, 배경은 검정색으로 변환해야 한다. 이후 흰색 부분에 대한 경계선만 검출하면 되는 것.
손가락 검출에서도 마찬가지다. 같은 색상 스펙트럼을 가진 부분끼리 영역을 나눠둔다.
이 과정에서 살색 부분의 영역이 검출되는 것이다. 영역을 나눈뒤에는 회색조의 이미지로 변환하고 살색부분의 영역을 흰색으로 변환해야한다.
왜 흰색으로 변환해야 하냐면.. cv2에서 제공하는 경계선 검출 함수가 회색조이미지를 디폴트로 하기 때문.
'(0, 1) > 손마리' 카테고리의 다른 글
| PYQT를 이용해 UI와 YOLO 연결 시키기 (0) | 2022.01.27 |
|---|---|
| 핵심 이미지 검출 시 단어 출력 (0) | 2022.01.27 |
| YOLO를 이용한 핵심 이미지 트레이닝 및 라벨링 (0) | 2022.01.27 |
| 수어 번역 프로그램(sign language translator in hospital) (9) | 2021.05.17 |
| 기존의 수어 번역 오픈소스 조사 (0) | 2021.04.24 |



