
0과 1 사이
[4장]손실함수, 미니배치, 기울기 구현 본문
손실함수
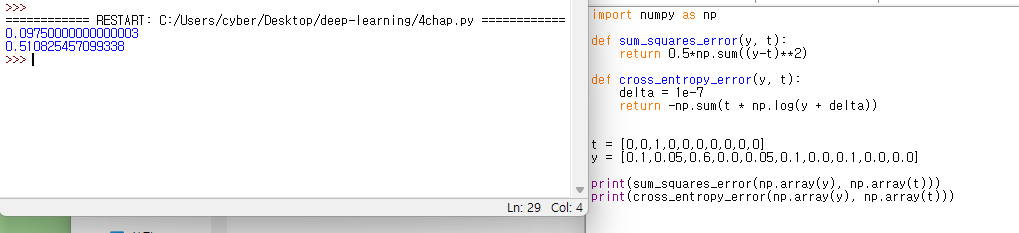
교차제곱 손실함수의 경우 모든 인덱스의 신경망 출력과 정답 레이블의 차를 제곱해 더하는 반면,
교차 엔트로피 손실함수의 경우 정답 인덱스만 계산에 들어간다. 정답 레이블인 t가 정답 인덱스만 1이고 나머지는 0인 원앤핫 인코딩으로 이루어져 있기 때문.
미니배치

훈련 데이터 모두를 이용하여 학습하고 그에 대한 손실함수를 모두 더하는 것은 시간관계상 매우 오래걸린다.
이에 따라 미니배치의 크기를 정해두고 전체 훈련 데이터에서 미니배치의 크기만큼 뽑아서 학습시키고, 손실함수를 계산한다.
tv 프로그램의 시청률을 계산할 때 무작위로 추출하여 계산한 다음 전체 시청률로 근사하는것과 비슷한 이치다.
왼쪽에 무작위로 선택한 인덱스들이 나타난다.
기울기
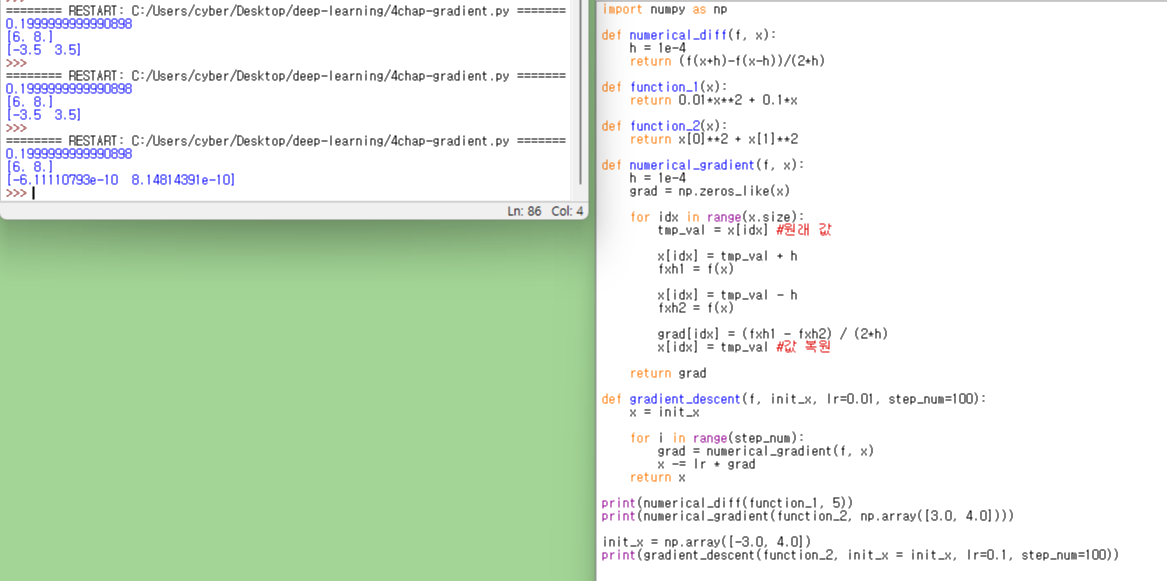
처음에는 최종 gradient_descent가 -3.5, 3.5로 나왔다.
알고보니 gradient_descent 구할때 grad = numerical_gradient를 numerical_diff로 잘못 써서 그런 것이다.
참고로 numerical_gradient 와 numerical_diff의 차이는 변수 개수의 차이이다.
다음은 학습률의 차이에 따른 기울기 값의 차이를 알아보기 위한 것이다.
처음 나온 기울기 값은 학습률이 지나치게 클때, 나중에 나온 기울기 값은 학습률이 지나치게 작을 때 이다.
그런데 어째서인지 둘 다 똑같은 값을 출력한다.

아마도 gradient_descent를 실행할 때 init_x 값을 아예 바꿔버리는 것 같다.
다시 init_x를 선언해줬더니 올바르게 출력된다. 왜일까?
gradient_descent는 그저 바뀐 x를 돌려주는 함수이고, init_x에 저장하지는 않는데.. 좀 생각이 필요할 것 같다.

어쨌거나 학습률이 너무 크면 발산해버리고, 반대로 너무 작으면 시작점에서 거의 변화가 없다는 것을 알 수 있다.
'딥러닝 공부' 카테고리의 다른 글
| 기존의 CNN을 활용한 수어 번역 오픈소스 조사 (0) | 2022.01.26 |
|---|---|
| [4장] 신경망에서의 기울기 계산 (0) | 2021.08.23 |
| [3장]신경망 예측, 정확도 계산, 배치 처리 (0) | 2021.08.19 |
| [2장]퍼셉트론 구현 (0) | 2021.08.09 |
| [3장]행렬 곱과 3층 신경망 구현 (0) | 2021.08.09 |



